
RStudioのプロジェクトについて
RStudioにはプロジェクト機能があります。プロジェクト機能とは、Rで行いたい基本的な環境を提供します。RStudioではデータ分析用の環境であったり、Rパッケージ用の環境であったり、shiny用の環境などがあらかじめ準備されています。特に、プロジェクト機能を使えば、データ分析は適切な粒度でファイル管理を行えますので、データごとにプロジェクトを作成することをおすすめします。
プロジェクトの作成
プロジェクトを作成するには、まず、File -> New Projectをクリックします。
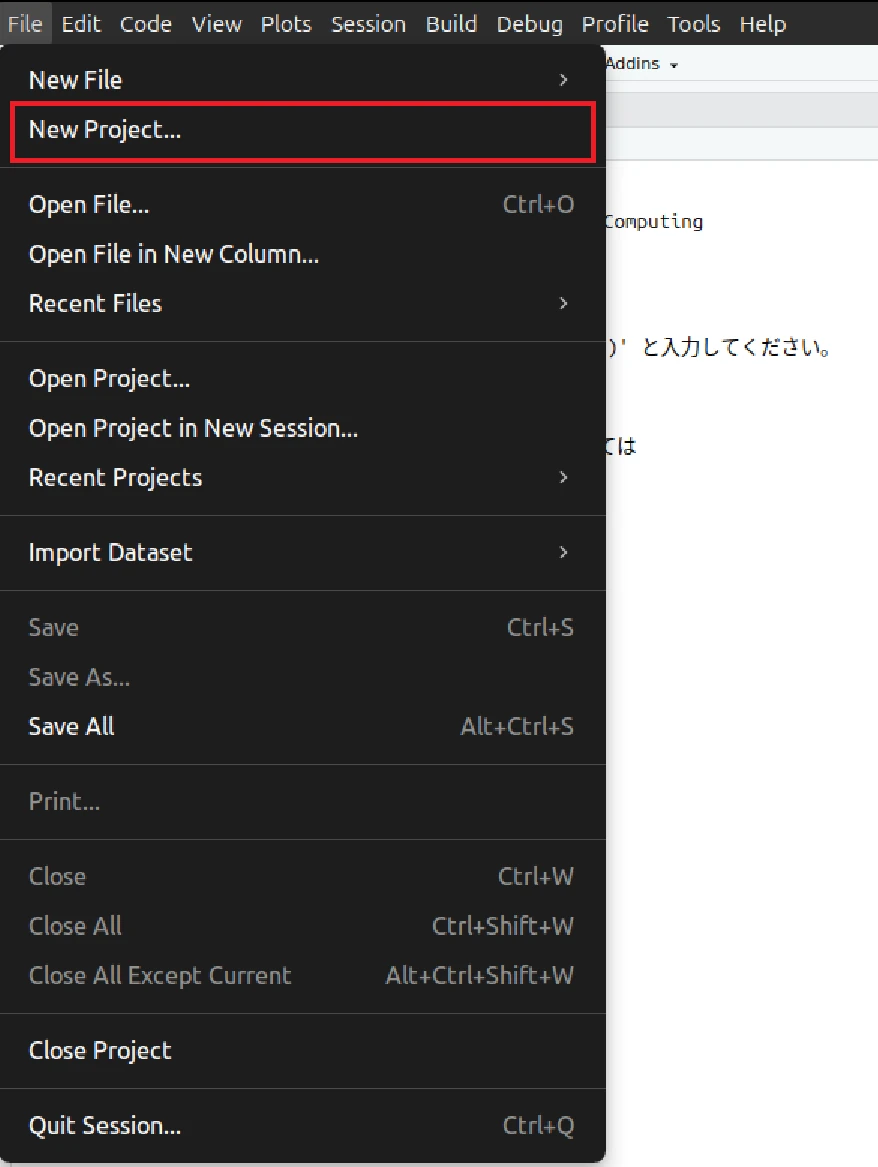
New Project Wizard画面が表示されます。
表示されている項目は次のような意味になります。
- New Directory: 新しいディレクトリを作成して、プロジェクトを作成します
- Existing Directory: すでに存在しているディレクトリを利用して、プロジェクトを作成します
- Version Control: GitやSubversionからプロジェクトをチェックアウトします
ここでは、New Directoryを選択します。
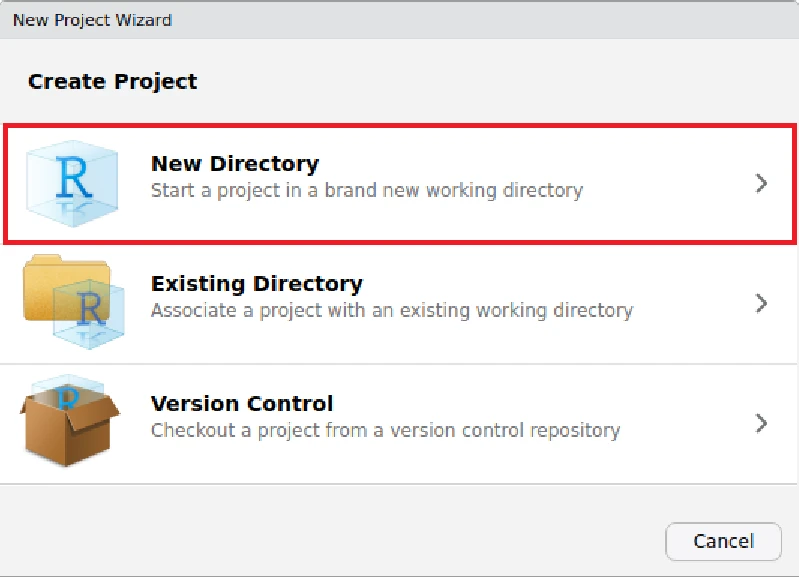
次にProject Typeを選択します。Project Typeごとにあらかじめ用意されるディレクトリ構造やファイルが異なるので、目的に叶ったProject Typeを選択します。ここではNew Projectを選択します。
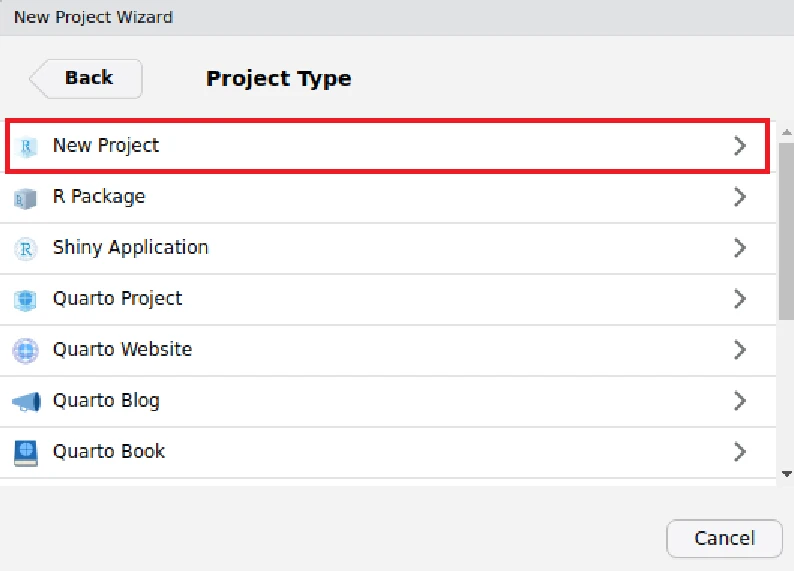
先ほど、New Directoryを選択したので、新たに作成するディレクトリ名とその親ディレクトリを指定します。
- Create a git repository: Gitリポジトリを作成します
- Use renv with this project: このプロジェクトでrenvによるパッケージ管理を行います
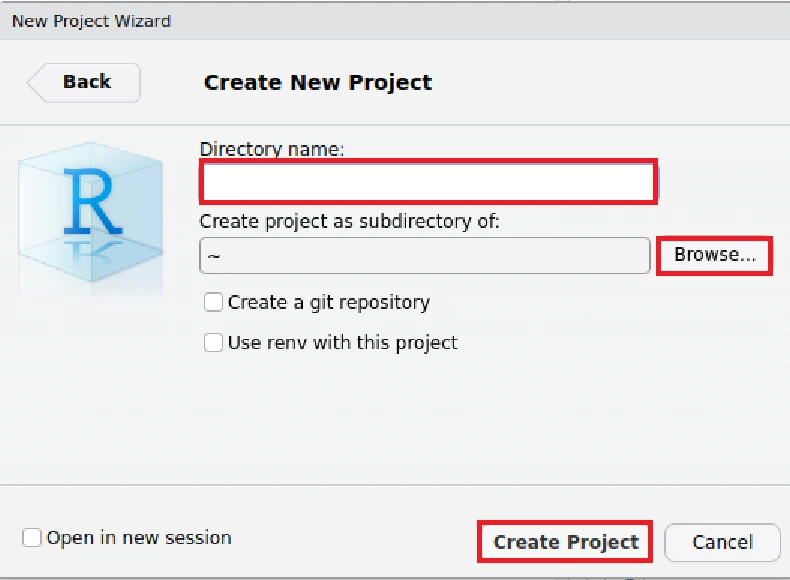
最後に、Create Projectを押下すればプロジェクトが作成され、RStudioが新たに作成したプロジェクトを開き直します。
Project TypeがNew Projectのときの構成
Project TypeがNew Projectのとき、隠しディレクトリとして.Rproj.userと[プロジェクト名].Rpojが自動的に作成されます。また、このプロジェクトを使用していくと、.RDataと.Rhistoryも追加されます。これらの意味は次になります。
- .Rproj.user: プロジェクト固有の一時ファイル(自動保存されたソースやドキュメント、ウィンドウの状態など)が保存される隠しディレクトリです
- [プロジェクト名].Rpoj: プロジェクトのメインファイルで、このファイルを実行するとRStudioでこのプロジェクトを開くことができます
- .RData: プロジェクトを開いた際に前回のオブジェクトを復元するための情報が保管されているファイル
- .Rhistory: コマンドの履歴が保管されているファイル
このため、Gitでバージョン管理する場合は、[プロジェクト名].Rpoj以外の「.Rproj.user」「.RData」「.Rhistory」の3つは.gitignoreに記載しておいた方が良いでしょう。
データ分析におすすめのディレクトリ・ファイル構成
ファイル管理に熱心でない方は、プロジェクト・ディレクトリ内に乱雑にファイルを配置してしまい、ファイル探索に時間をとられるなど効率的でない場面によく遭遇します。そこで、私のおすすめのディレクトリ構成を紹介します。
- master_data: 元データの保管場所。上書きなど、絶対に変更しない
- analytics_data: master_dataを加工してデータ分析用として準備したデータの保管場所
- output: グラフやCSVファイルなどの出力データの保管場所
- rmarkdown: rmarkdownファイルの保管場所
- script: scriptファイルの保管場所
現在においては、scriptファイルの出番があまり多くなく、おおよそ共通処理が記載されているだけであることと思います。そのため、ある一定規模以上のデータ分析となると、必然的にrmarkdownディレクトリ内にファイルが多くなりやすいです。このとき、RMarkdownのファイル名を適切に設定しないと、RMarkdownのファイル間の依存関係がよく分からず、把握するのに時間をとられ非効率です。私のおすすめとしては、ファイル名の先頭に「00_」などの接頭辞を付けることです。例えば、次のようになります。
- 00_データ作成: マスターデータかデータ分析用データの作成
- 10_基本統計量: 基本統計量の一覧
- 11_度数分布表: 度数分布表の一覧
- 12_散布図: 項目間の散布図の一覧
- 20_クラスタリングA: アルゴリズムAによるクラスタリング
- 21_クラスタリングB: アルゴリズムBによるクラスタリング
- 22_クラスタリング比較: クラスタリングAとクラスタリングBの比較
- 30_クラスターの影響力: クラスター間の影響力調査
このような接頭辞を付ければ、ファイル名の段階で依存関係が把握しやすくなります。