ここで言う平均的に分類するというのは、分類された各グループのデータ数がほぼ等しく、かつ、分類された各グループの平均値が定量データ全体の平均値にほぼ等しくなるように分類するということである。
具体的には、学生のクラス替えを行う際に、100人の学生を3つのクラスに振り分けたいが、その場合、各クラスの人数がほぼ等しく、また、各クラスの文系能力と理系能力の平均値もほぼ等しく分けるにはどうしたらよいのかについて考えてみる。
実際に分類を行うのは、手作業で行うわけにはいかないので、プログラムを組むことにする。ここでは、C#(.net framwork4.0)を用いることにした。
インターネット上でこのような分類方法またはソースコードについて検索してみたが、検索の仕方が悪いのか良い情報にめぐり合わなかったので考えてみた。このような分類方法に詳しいウェブサイトをご存知だったら教えていただけたら幸いだ。
では、さっそく考察していく。
具体的に考えたほうが分かりやすいので、100人の学生を3つのクラスに分ける方法を考えてみる。定量データは100人の学生の国語と数学の点数が与えられているとしよう。
つまり、Aクラス34人、Bクラス33人、Cクラス33人の3つクラスで、各クラスの国語と数学の点数の平均値がほぼ等しくなるように分けるにはどうすればよいのかを考えてみる。
まず、最初に思いついたのは、学生を平均値に近い学生順に並び替えをして、この順でAクラス→Bクラス→Cクラス→Aクラス→・・・と割り当てていけば、最終的に、3つのクラスの平均値がほぼ等しくなるのでは、ということだ。
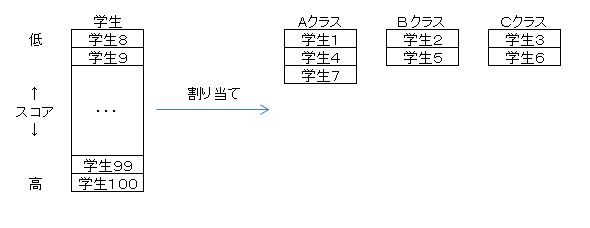
そこで問題となるのが、学生の並び替えだ。ここでは、以下の算式でスコアを出して、このスコアによって並び替えを行うこととした。^2は()内の数値を二乗するということである。
スコア=(国語の点数-全学生の国語の平均点)^2+(数学の点数-全学生の数学の平均点)^2
それでは、実際にC#で組んでみる。
ここからは、少し一般化しているので注意して欲しい。
まず、定性データの入れ物として以下のクラスを準備する。
public class Item
{
private double[] _values;
public double[] Values { get { return _values; } }
public Item(double[] values)
{
_values = values;
}
}
次に、グループ分けされた定量データの入れ物として以下のクラスを準備する。コンストラクタのvalueIndeicesはItemクラスのValueプロパティのうち、どのインデックスが平均値に採用されたかを表すものである。
public class Group
{
private IEnumerable _valueIndices;
private IList- _items = new List
- ();
public IList
- Items { get { return _items; } }
public Group(IEnumerable
valueIndices)
{
_valueIndices = valueIndices;
}
public IDictionary Average()
{
var dictionary = new Dictionary();
foreach (var valueIndex in _valueIndices)
{
dictionary[valueIndex] = _items.Average(x => x.Values[valueIndex]);
}
return dictionary;
}
}
実際の分類は以下のクラスで行う。
public class SequentialClassification
{
public IEnumerable Classify(IEnumerable- source, IEnumerable
valueIndices, int groupNumber)
{
//平均値
var averageDictionary = new Dictionary();
foreach (var valueIndex in valueIndices)
{
averageDictionary[valueIndex] = source.Average(x => x.Values[valueIndex]);
}
//スコア計算
var scoreDictionary = new Dictionary();
foreach (var item in source)
{
var d = 0.0d;
foreach (var valueIndex in valueIndices)
{
var v = (item.Values[valueIndex] - averageDictionary[valueIndex]);
d += v * v;
}
scoreDictionary[item] = d;
}
//スコアを昇順に並び替え
var list = new List>(scoreDictionary);
list.Sort((x, y) => x.Value.CompareTo(y.Value));
var items = list.Select(x => x.Key).ToArray();
//グループ作成
var groups = new List();
for (var i = 0; i < groupNumber; i++)
{
groups.Add(new Group(valueIndices));
}
//グループ振り分け
var count = items.Count();
for (var i = 0; i < count; i++)
{
groups[i % groupNumber].Items.Add(items[i]);
}
return groups;
}
}
以上で、準備は完了だ。それでは、実際に分類してみる。定性データは乱数を用いてダミーデータを作成した。
public class Test
{
public void Test1()
{
//ダミーデータ作成
var items = new List- ();
for (var i = 0; i < 100; i++)
{
var random = new Random(i);
var values = new double[2];
values[0] = random.Next(0, 100);
values[1] = random.Next(0, 100);
items.Add(new Item(values));
}
//分類
var classification = new SequentialClassification();
var groups = classification.Classify(items, new int[] { 0, 1 }, 3);
//ダミーデータ表示
System.Console.WriteLine("dummy-data");
foreach (var item in items)
{
System.Console.WriteLine(item.Values[0] + "," + item.Values[1]);
}
//ダミーデータの平均値の表示
System.Console.WriteLine("dummy-data-average");
System.Console.WriteLine("0:" + items.Average(x => x.Values[0]));
System.Console.WriteLine("1:" + items.Average(x => x.Values[1]));
//結果表示
foreach (var group in groups)
{
System.Console.WriteLine("group-item");
foreach (var item in group.Items)
{
System.Console.WriteLine(item.Values[0] + "," + item.Values[1]);
}
System.Console.WriteLine("group-average");
var dictionary = group.Average();
foreach (var kvp in dictionary)
{
System.Console.WriteLine(kvp.Key + ":" + kvp.Value);
}
}
}
}
この結果は以下のようになった。
| 全データ | グループ1 | グループ2 | グループ3 | |
| インデックス0の平均値 | 51.12 | 55.85 | 44.78 | 52.57 |
| インデックス1の平均値 | 50.66 | 56.05 | 50.06 | 45.69 |
やはりと言うべきだが、精度が悪い。特に、インデックス0と1のバラツキが大きい。この理由は明らかで、各インデックスに対しての平均値をまったく考慮していないからである。次回は、各インデックスの平均値を考慮したものを考えてみる。

")
